TensorFlow实现AutoEncoder自编码器,
TensorFlow实现AutoEncoder自编码器,
一、概述
AutoEncoder大致是一个将数据的高维特征进行压缩降维编码,再经过相反的解码过程的一种学习方法。学习过程中通过解码得到的最终结果与原数据进行比较,通过修正权重偏置参数降低损失函数,不断提高对原数据的复原能力。学习完成后,前半段的编码过程得到结果即可代表原数据的低维“特征值”。通过学习得到的自编码器模型可以实现将高维数据压缩至所期望的维度,原理与PCA相似。
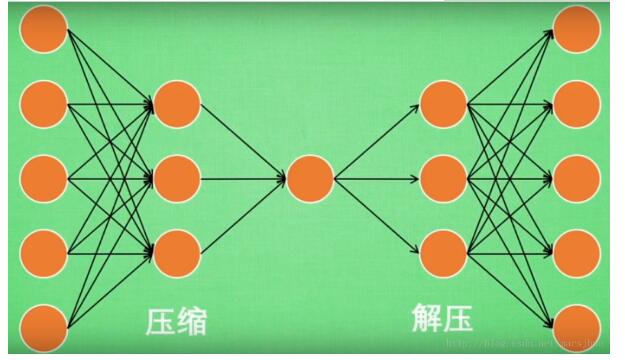
二、模型实现
1. AutoEncoder
首先在MNIST数据集上,实现特征压缩和特征解压并可视化比较解压后的数据与原数据的对照。
先看代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入MNIST数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
learning_rate = 0.01
training_epochs = 10
batch_size = 256
display_step = 1
examples_to_show = 10
n_input = 784
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input])
# 用字典的方式存储各隐藏层的参数
n_hidden_1 = 256 # 第一编码层神经元个数
n_hidden_2 = 128 # 第二编码层神经元个数
# 权重和偏置的变化在编码层和解码层顺序是相逆的
# 权重参数矩阵维度是每层的 输入*输出,偏置参数维度取决于输出层的单元数
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
# 每一层结构都是 xW + b
# 构建编码器
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# 构建解码器
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
# 构建模型
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
# 预测
y_pred = decoder_op
y_true = X
# 定义代价函数和优化器
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2)) #最小二乘法
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
# 首先计算总批数,保证每次循环训练集中的每个样本都参与训练,不同于批量训练
total_batch = int(mnist.train.num_examples/batch_size) #总批数
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
代码解读:
首先,导入将要使用到的各种库和数据集,定义各个参数如学习率、训练迭代次数等,清晰明了便于后期修改。由于自编码器的神经网络结构非常有规律性,都是xW + b的结构,故将每一层的权重W和偏置b的变量tf.Variable统一置于一个字典中,通过字典的key值更加清晰明了的描述。模型构建思路上,将编码器部分和解码器部分分开构建,每一层的激活函数使用Sigmoid函数,编码器通常与编码器使用同样的激活函数。通常编码器部分和解码器部分是一个互逆的过程,例如我们设计将784维降至256维再降至128维的编码器,解码器对应的就是从128维解码至256维再解码至784维。定义代价函数,代价函数表示为解码器的输出与原始输入的最小二乘法表达,优化器采用AdamOptimizer训练阶段每次循环将所有的训练数据都参与训练。经过训练,最终将训练结果与原数据可视化进行对照,如下图,还原度较高。如果增大训练循环次数或者增加自编码器的层数,可以得到更好的还原效果。
运行结果:
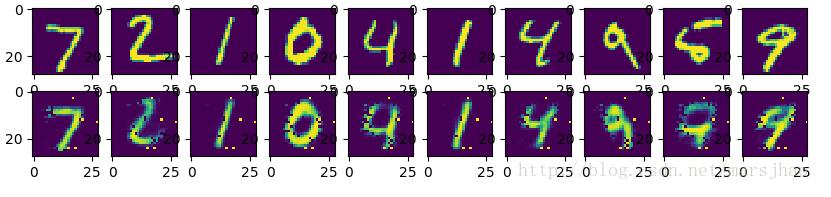
2. Encoder
Encoder编码器工作原理与AutoEncoder相同,我们将编码得到的低维“特征值”在低维空间中可视化出来,直观显示数据的聚类效果。具体地说,将784维的MNIST数据一步步的从784到128到64到10最后降至2维,在2维坐标系中展示遇上一个例子不同的是,在编码器的最后一层中我们不采用Sigmoid激活函数,而是将采用默认的线性激活函数,使输出为(-∞,+∞)。
完整代码:
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
learning_rate = 0.01
training_epochs = 10
batch_size = 256
display_step = 1
n_input = 784
X = tf.placeholder("float", [None, n_input])
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
# 为了便于编码层的输出,编码层随后一层不使用激活函数
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
y_pred = decoder_op
y_true = X
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
with tf.Session() as sess:
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
plt.colorbar()
plt.show()
实验结果:
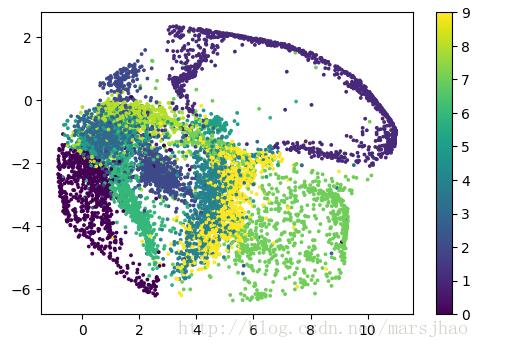
由结果可知,2维编码特征有较好的聚类效果,图中每个颜色代表了一个数字,聚集性很好。
当然,本次实验所得到的结果只是对AutoEncoder做一个简单的介绍,要想得到期望的效果,还应该设计更加复杂的自编码器结构,得到区分性更好的特征。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持帮客之家。
相关内容
- TensorFlow神经网络优化策略学习,tensorflow网络优化
- tensorflow创建变量以及根据名称查找变量,tensorflow变量
- TensorFLow用Saver保存和恢复变量,tensorflowsaver
- TensorFlow saver指定变量的存取,tensorflowsaver
- TensorFlow平台下Python实现神经网络,tensorflowpython
- TensorFlow 实战之实现卷积神经网络的实例讲解,tensorf
- tensorflow入门之训练简单的神经网络方法,tensorflow神经
- 用tensorflow构建线性回归模型的示例代码,tensorflow示例
- 利用TensorFlow训练简单的二分类神经网络模型的方法,
- 用tensorflow搭建CNN的方法,tensorflow搭建cnn
评论关闭